The Problem
Have you ever faced the daunting task of renaming a massive amount of files stored in Amazon S3? Out of the box, AWS does not provide a direct method to rename (Linux - mv) files in S3. The naive approach is to copy each existing file with a new keyname and delete the old one. Using the AWS CLI, that can look something like this:
|
aws s3 cp s3://<SOURCE_KEYNAME> s3://<DESTINATION_KEYNAME> --recursive |
While this may be a fine approach for a few files or a specific directory, for one of our clients, this challenge arose when they needed to rename 2.66M (34.6TB) production image files.
Our client, a global scale media conglomerate, accumulated a large repository of image files stored in an S3 Bucket. However, these files were named using UUIDs making it challenging for their new Digital Asset Management (DAM) system to work effectively. They approached our team with a request to rename these files based on a mapping provided in a CSV file containing UUIDs and corresponding filenames. The file looked something like this:
|
uuid,fileName |
While there are methods of invoking lambda functions in parallel (fan-out pattern), I was determined to find a better tool for the job that required less operational overhead as this was a pressing issue.
What is S3 Batch Operations?
Amazon S3 Batch Operations is a managed solution designed for performing large-scale batch operations on S3 objects using a manifest file. According to the AWS documentation, S3 Batch Operations can perform actions across billions of objects and petabytes of data with a single request. This service can also process multiple objects in parallel and provides built-in error handling.
1. S3 Batch Operations can be used to perform the following job types:
2. Copy Objects to the required destination
3. Replace all object tags
4. Delete all object tags
5. Replace Access Control Lists (ACLs)
6. Restore archived objects
7. Enable Object Lock
8. Enable Object Lock legal hold
9. Invoke AWS Lambda function to perform a complex operation
Being that none of the 7 out of the box operations will solve the task of copying and renaming the objects, we opted for invoking a custom AWS Lambda function.
Generating Manifest with Task-Level Information
A manifest file serves as a blueprint for batch processing jobs, outlining the specific parameters and data needed for execution. It ensures that each task within the batch is precisely defined, facilitating efficient and accurate processing by the Lambda function.
The format for a manifest file can be different per job type. Because we have a task that requires per-key parameters to be used in our Lambda function’s code, we must use the following URL-encoded JSON format. The key field is passed to the Lambda function as if it were an Amazon S3 object key, but it can be interpreted by the Lambda function to contain other values or multiple keys. Please note, the maximum number of characters for the key field in the manifest is 1,024.
Given, we have a UUID to Destination Filename map, we can write a simple python script to generate the manifest file for our batch job.
|
import csv with open(output_csv, 'w', newline='') as outfile: if __name__ == "__main__": |
Based on the CSV Filemap provided earlier, this script will output the following to manifest.csv:
|
S3_BUCKET_NAME,%7B%22sourceKeyname%22%3A%20%22123e4567-e89b-12d3-a456-426655440000%22%2C%20%22destinationKeyname%22%3A%20%22images/image1.jpg%22%7DS3_BUCKET_NAME,%7B%22sourceKeyname%22%3A%20%22234e5678-e89b-12d3-a456-426655440001%22%2C%20%22destinationKeyname%22%3A%20%22images/image2.jpg%22%7DS3_BUCKET_NAME,%7B%22sourceKeyname%22%3A%20%22345e6789-e89b-12d3-a456-426655440002%22%2C%20%22destinationKeyname%22%3A%20%22images/image3.jpg%22%7D |
Note, S3 Batch Operations expects no header row within the manifest file. We will want to take this manifest file and upload it at the root of our bucket.
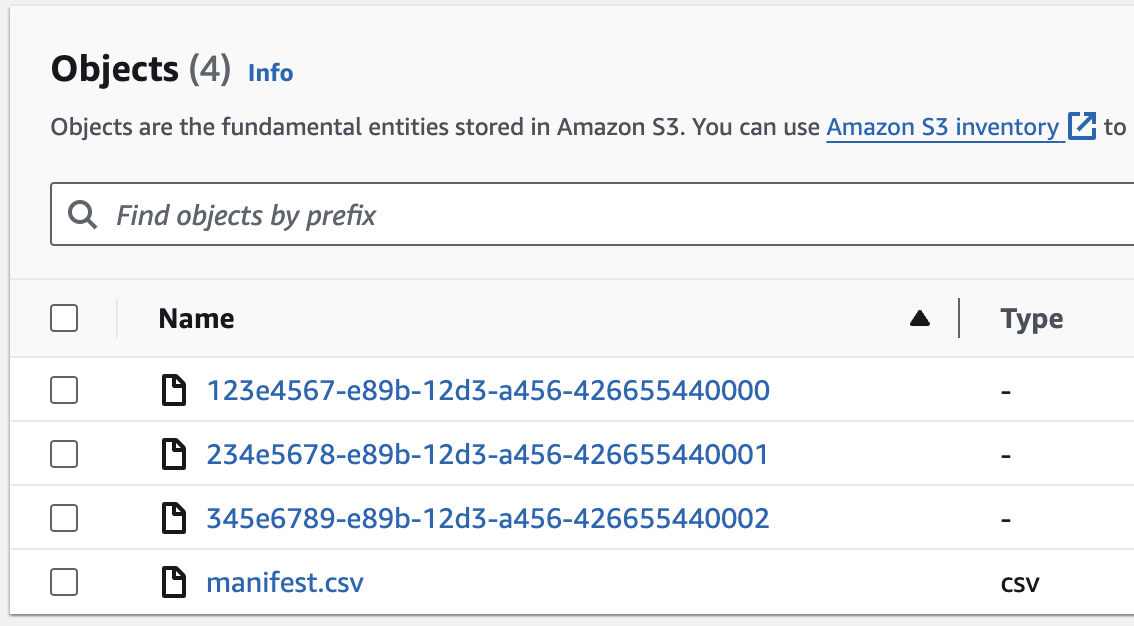
Before we can set up the Batch Job, we must create the Lambda function that will be doing the operation. Provided below is the Python code that will perform the renaming operation. Be sure to add proper permissions to the Lambda Execution Role. For more information on Lambda Execution Roles, see the AWS Docs. The code returns the provided payload for the batch operations to give us an accurate result in the completion report.
|
import boto3
results = [] |
Setting up the Batch Job
At the time of writing, there is no support through Infrastructure as Code tools (CloudFormation, CDK, Terraform) to create batch jobs. This is easily done through the console. This is a fine approach for one-off jobs, but if building a recurring batch job, it may be a better approach to use the CLI and store the command in source control or something similar.
On the left hand side of the Amazon S3 Console, there will be a selection for Batch Operations. We will then select Create Job. To start, we will have to configure the manifest file that is stored at the root of our bucket.
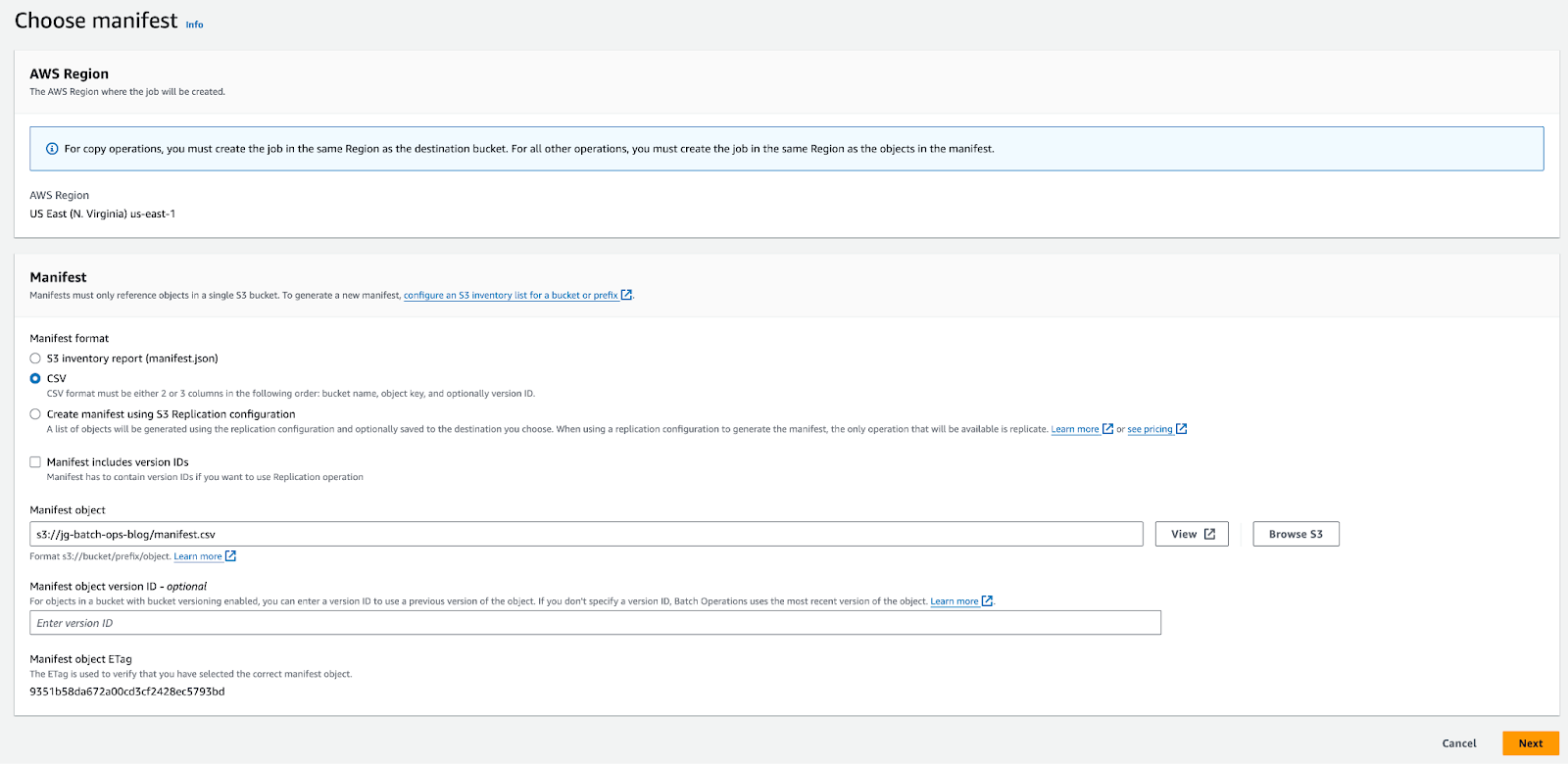
We will then need to select the Operation Type. For our use case, we will select Invoke AWS Lambda Function. This will allow us to provide custom functionality to our Batch Operation. This will allow us to then go forward and select our Lambda function that we created in previous steps.
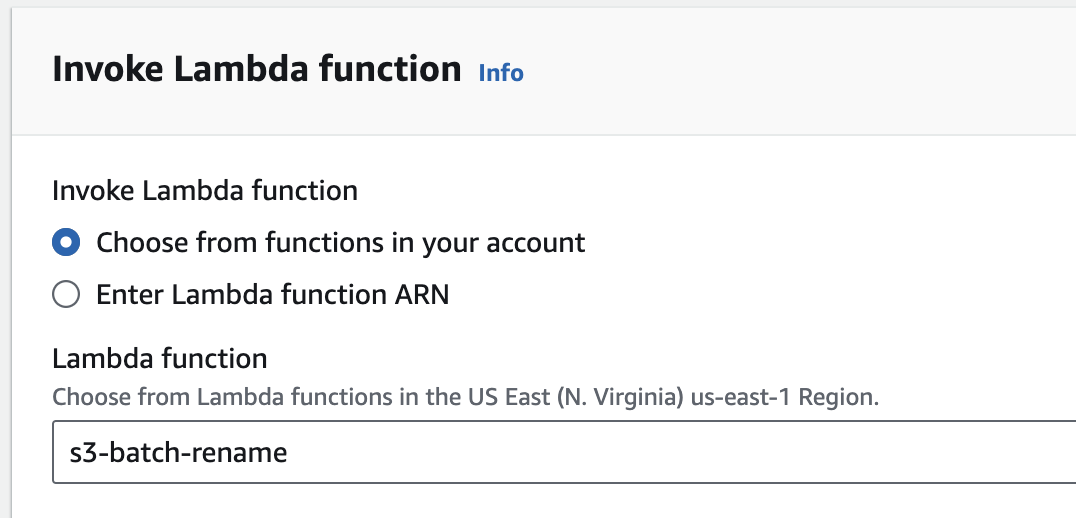
The next important step is to configure the Completion Report. This will generate a CSV report that can list successes and failures. According to AWS, the reports are encrypted using SSE-S3. For the purpose of this demo, we will write the completion reports to a folder in the bucket named reports and only include failed tasks. This can greatly simplify parsing the report when dealing with large scale operations.
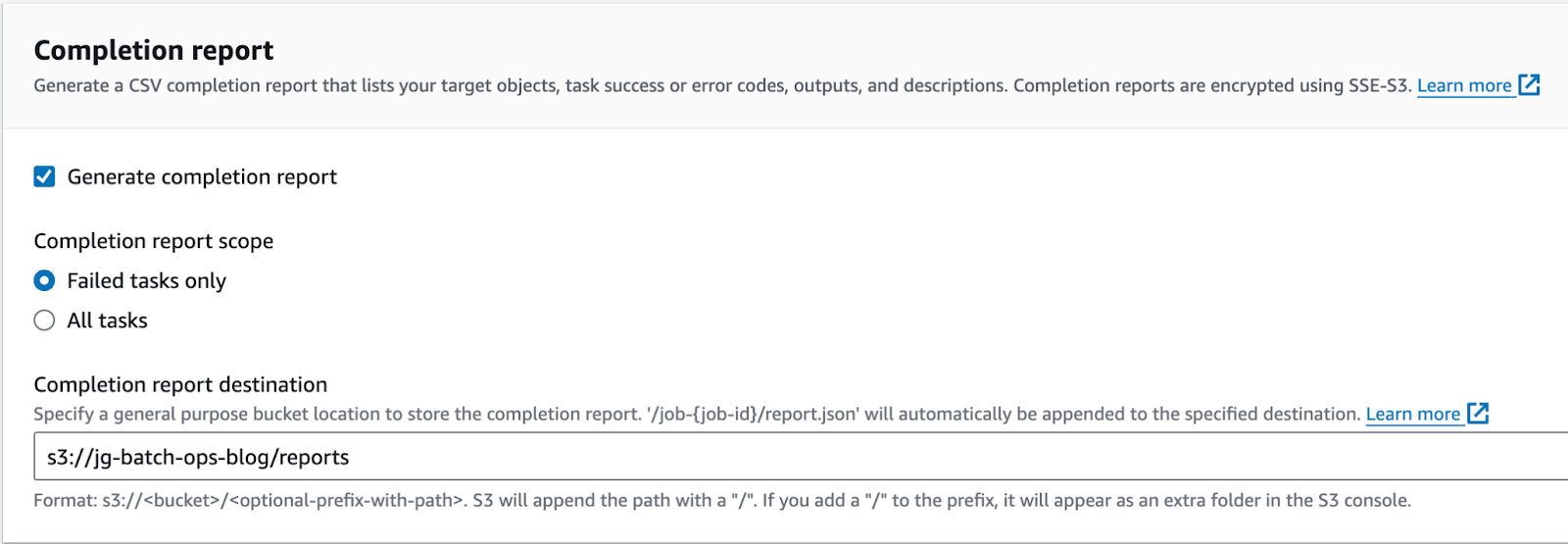
Next, be sure to set the correct permissions for your batch job to run. Please see https://docs.aws.amazon.com/AmazonS3/latest/userguide/batch-ops-invoke-lambda.html to learn more about setting up the S3 Batch Operations trust policy & other required permissions.
After this, we can create the job, and it should show in the main console. On creation, the batch job will parse the manifest file specified, check for errors, and also give you the total number of objects expected to be operated on. In our case, we currently have 3 files to be renamed.

After running the job, we should be able to see the details while the job is running. After 7 seconds, my job successfully completed for all 3 files.
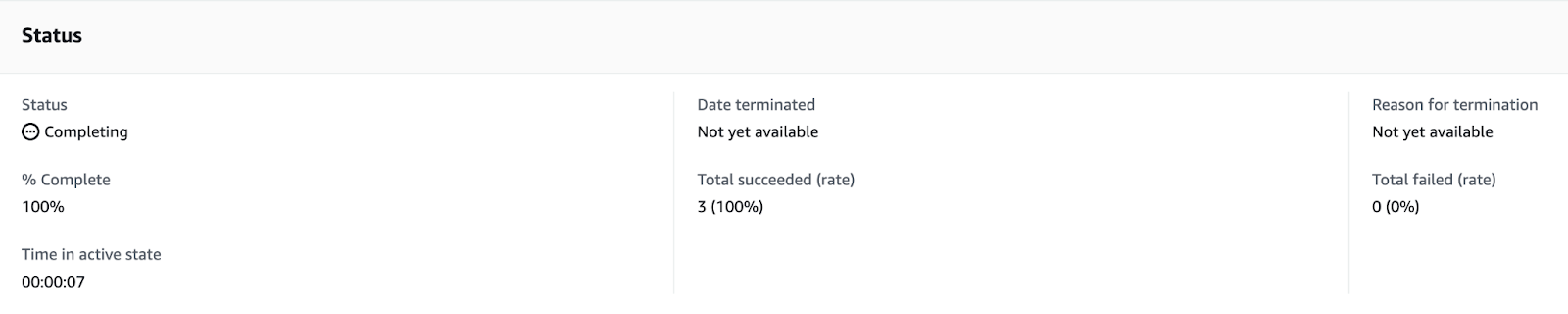
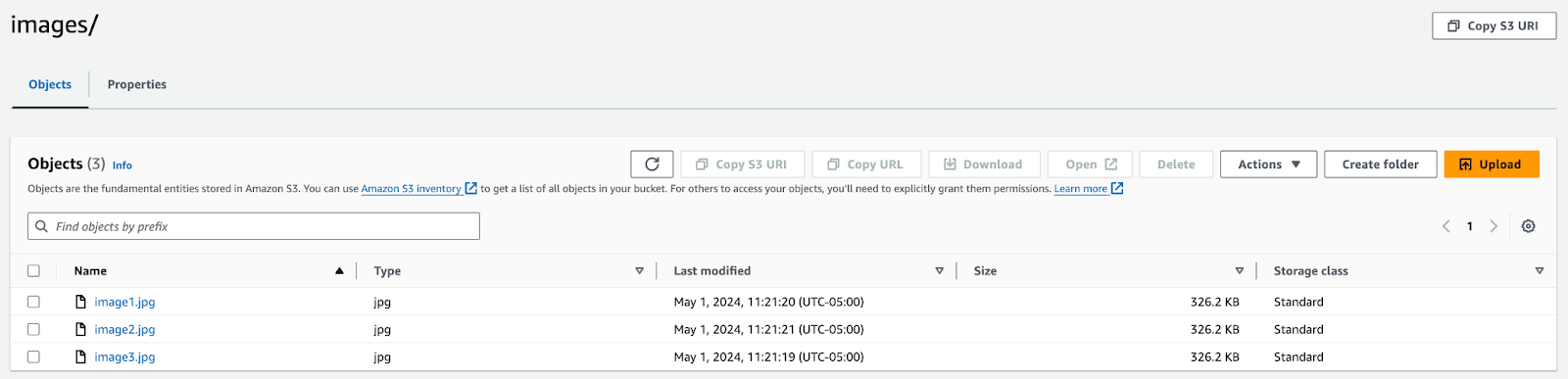
This is a helpful view when paired with the completion report to troubleshoot different scenarios that may cause issues. When moving back over to the S3 Bucket, we can see the files have been renamed and moved under a new directory. The original files have been deleted from the bucket.
Conclusion
S3 Batch Operations are an extremely powerful tool when used correctly. They can be incredibly efficient without adding much additional cost. For our use case with the client (2.66M files), when compared with a Java Spring service using the AWS SDK to make Copy and Delete requests for each file, we saw a reduction from 30 hours of compute to 40 minutes - 98.8% reduction. While this was a one time job, S3 Batch Operations makes it easy to perform recurring batch jobs as well. If you have a project that is currently using or is a candidate for AWS, contact Jahnel Group to see how we might be able to work with you.
.png?width=731&height=731&name=Untitled%20design%20(9).png)
Author Bio
Matthew Spahr is a Software Engineer at Jahnel Group, Inc., a custom software development firm based in Schenectady, NY. At Jahnel Group, we're passionate about building amazing software that drives businesses forward. We're not just a company - we're a community of rockstar developers who love what we do. From the moment you walk through our door, you'll feel like part of the family. To learn more about Jahnel Group's services, visit jahnelgroup.com or contact Jon Keller at jkeller@jahnelgroup.com
.png)
.png)
