In my previous blog post we embarked on a quest to find insights from my Apple Health data. I completed data cleaning and exploration to prepare my data set for my main quest, to see if I can predict if I’ll have a good or bad night's sleep based on the workout types and durations I did that day. I’ve created my character for this quest, a data set using my Apple Health workout and sleep data. With my sidequests complete and my dataset leveled up I am ready to take on the main quest and face the final boss, my model. \
My final data set definition is below and each data point is aggregated to the day level.
Gym: Amount of time working out at the gym.
PSF (name of my fitness studio): Amount of time doing functional strength fitness class.
Tennis: Amount of time playing tennis
Walking: Amount of time walking for exercise
BelowAvg: Binary variable where 1 indicates that my time awake during sleep was at or below 9% of all my sleep cycles in one night. This is considered good sleep.
From my previous exploration I decided that I wanted to try three different models; Logistic, XGBoost, and Random Forest. Continuing my video game analogy this could be similar to deciding what type of equipment you want your character to have. All of your options could work, but some will perform better than others.
Logistic: Fits the data to a logistic function to predict probabilities of an object falling into a binary classification. It is easy and efficient to use as the logistic function models the probability of an event happening.
Random Forest: Creates groups of decision trees to calculate the probability of an event. This is useful as it’s using multiple attempts at a scenario to create the best results.
XGBoost: Extreme Gradient Boosting (XGBoost) is like giving Random Forest a power up. Boosting is when the model learns from its previous mistakes and attempts to correct them. So each additional tree has learned from the previous, improving its prediction.
No matter the model, the first step is to split my data into training and testing. Python makes this easy with a couple lines of code.



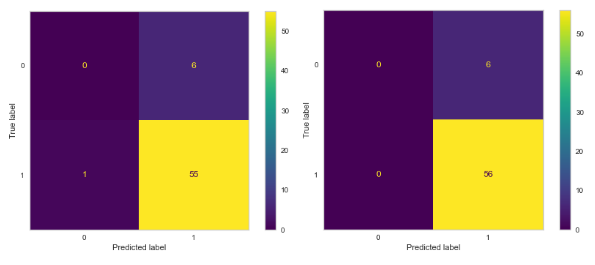
Just like that I’ve defeated the final boss and now have three predictive models… that was too easy. Cue cut scene of the final boss rising up ready to go another round. This fight isn’t over yet. I need to check the diagnostics of my model. Since this is a classification problem, I will equip my next weapon, the confusion matrix. The confusion matrix allows me to easily visual my model’s predictive power. For more uses of the confusion matrix take a look at my blog post here.
My Random Forest and XGBoost models result in the same confusion matrix (left). On the right, my Logistic model was able to perform better correctly classifying 56 of the 62 data points.
It looks like Logistic is my best model but before taking it with me to the next round, let’s make sure it's the one that will help me succeed. I can calculate accuracy, precisions, specificity, sensitivity, and area under curve (AUC) of my models. Once again I’m given a choice. All these metrics could help me win this battle, but which will aid me the best in completing my goal? To make this choice let's review what these metrics are and how they could help me.
Accuracy is the overall correctness of a model’s predictions and the ratio of all correct predictions over all predictions. In this case it’s the percent of times the model correctly predicted that I would have a good or bad sleep.
Precision is the model's ability to correctly predict positive predictions from all positive instances. Here, it would be the number of times my model correctly predicted I would have a good night's sleep over all the predictions of good night sleep.
Sensitivity is also a measure of positive predictions but instead it’s comparing the correct positive predictions out of the actual positives. So it would be the amount of correct positive good sleep predictions over all good sleep events.
Specificity is the ability to correctly predict negative instances out of all negative occurrences.
Area Under Curve (AUC) is a measure of the tradeoff between specificity and sensitivity in the model.
Accuracy and AUC are metrics that will give me a good idea of my models performance. Both will show me overall, my models ability to make accurate predictions overall. My logistic model has the highest of these metrics so this is the model I’ll use.

Accuracy of .9 and AUC of 1, wow, we have a strong model! With this we can easily take on the boss and predict a good night’s sleep! Or not… with a killer move the final boss takes me down. What went wrong?
![]()
The specificity of my model is 0. I favored one attribute too strongly and left my character vulnerable. My model is great at identifying a good night's sleep but that’s all it's doing, it doesn’t once predict I will have a bad night's sleep.
To figure out the root cause, I need to go back to my exploration. I have a good idea of what took me down and need to do a quick side quest to see what was the percentage of good to bad sleep I had. Of my 153 data points only 12 of them were classified as bad sleep. I have an unbalanced data set.
Time to retrain. I want to oversample my data where I had poor sleep so my model can better predict when these events occur. I care about correctly predicting if I’ll have a bad night's sleep as that is what I would like to avoid. This means sensitivity is my main focus, not accuracy. With my new strategy, I’m ready to have another go at the final boss.
Using my oversampled data, I create new train and test data which I run through a Logistic model. I ease through the first two battles and time for the moment of truth, my model can correctly predict a bad night’s sleep but is it strong enough? Reviewing my evaluation metrics, it's not looking good. Most of my metrics are at or below .5 meaning a coin flip would be a better predictor.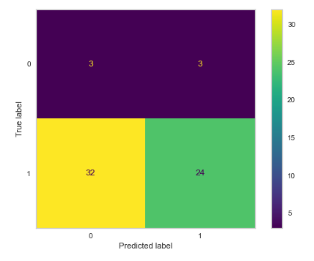

In a last ditch effort I use a power up and try to adjust my thresholds for assignment resulting in the following: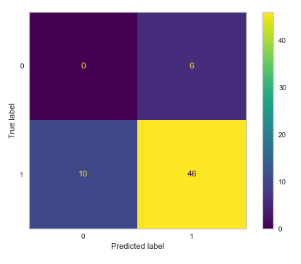

Down to my last one percent of health I barely make it through defeating the final boss. My model does predict a poor night’s sleep but not well. While I was able to complete my quest, it wasn’t my (or my model’s) best performance.
The good news is, like a video game, creating a machine learning model isn’t a one and done experiment. There’s still side quests I can go back and complete that can impact the ending. I can explore outside of my Apple Health data to find other variables that may impact my sleep or reconsider the build of the dataset with the data I have available. I could try different equipment to better tune my model and if all that still isn’t enough, I can wait for the expansion pack where I have more data to add into my model. I’ll put this game back on the shelf for now but know I can always come back and play again!
![]()
Author Bio
Jen Brousseau is a business analyst at Jahnel Group, Inc., a custom software development firm based in Schenectady, NY. Jahnel Group is a consulting firm that specializes in helping companies leverage technology to improve their business operations. We provide end-to-end strategic consulting and deployment services, helping companies optimize their operations and reduce costs through the use of technology. Jahnel Group is an Advanced Tier AWS Services Partner, with expertise in AWS Lambdas, Amazon API Gateway, Amazon DynamoDB, and other AWS services.
.jpg)
.jpg)
